Jasper Playing Jazz, Jazzoo


Published in 2024 IEEE International Conference on Image Processing (ICIP), 2024
Recommended citation: W. Hu, J. Liu, J. Wang and H. Tian, "Meta-DM: Applications of Diffusion Models on Few-Shot Learning," 2024 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 2024, pp. 773-779, doi: 10.1109/ICIP51287.2024.10647300. https://arxiv.org/pdf/2305.08092
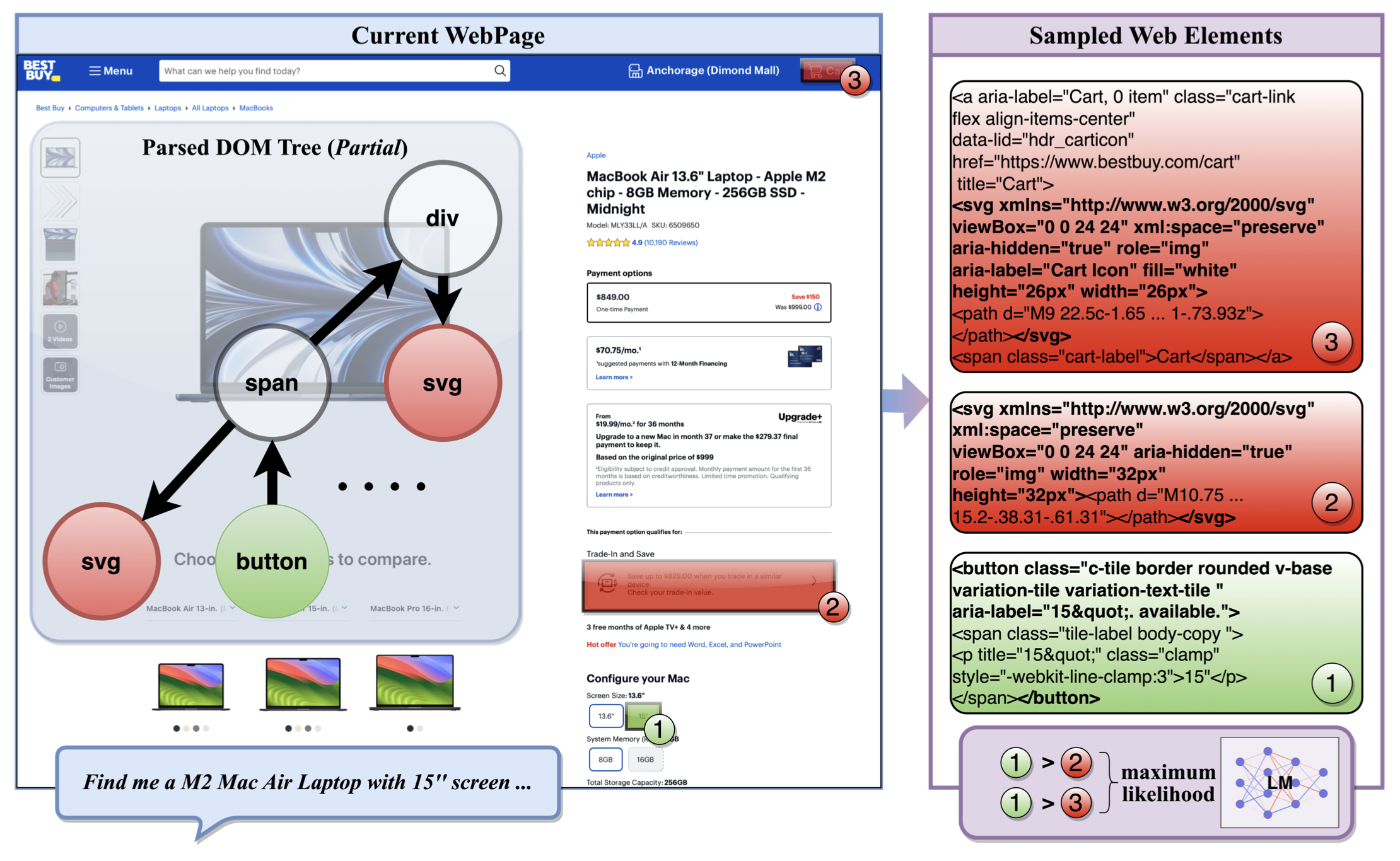
Published in 39th AAAI Conference on Artificial Intelligence (AAAI-25 Oral), 2024
Recommended citation: Jiarun Liu, Jia Hao, Chunhong Zhang and Zheng Hu. 2025. WEPO: Web Element Preference Optimization for LLM-based Web Navigation. In Proceedings of the 39th AAAI Conference on Artificial Intelligence (AAAI-25), Philadelphia, Pennsylvania, USA. https://ojs.aaai.org/index.php/AAAI/article/view/34863
Published:
An overview of knowledge graph principles, KGE, knowledge acquisition, and major applications is presented.
Published:
Mainly prompt experiment, no large deal. Working on bias and skewed margin, now a popular field.
Published:
The mainstream algorithms and developments in hierarchical reinforcement learning are described in detail, from theory to mainstream algorithms.
Published:
The research proposes a new paradigm for large models to implement reasoning about the physical world Mind’s Eye, by getting information from real simulations of physical problems in the Mujoco physics engine, and inputting auxiliary information along with the problems themselves to enable large models, the improvement in UTOPIA baseline is significant and can be done so that small models plus simulations can outperform large models after the effect improvement is significant.
Published:
CoT is a form of discrete cue learning. More specifically, contextual learning of language models adds many textual logical representations of thought in between compared to the previous traditional contextual learning (i.e., a series of texts as input for the large model to complete the output).
Published:
A paper writing try, also get to summrize the HRL knowledge.
Published:
We have read an important paper on option-based hierarchical reinforcement learning, The Option-Critic Architecture, and have critically reviewed the derivation of the equations to understand the SMDP process in option-state augmented space and the corresponding algorithmic framework.
Published:
CoT was already available when BIG-Bench first came out, but CoT did not perform well on small scale models (emergent effect could not be achieved), so BIG-Bench did not mention using CoT; but after that, PaLM / Davinci-002 / code-davinvi-002 and other larger scale models appeared. So there was a motivation to verify the effect of CoT on the new baseline of BIG-Bench. Sure enough, CoT is indeed better for many tasks.
Published:
The article describes what LLM is, how it is trained and works, and how it works, and then shows that LLM is also brittle and can make mistakes when disturbed. The article points out that there are two opposing voices, one arguing that this is the budding of general intelligence, and the other arguing that LLM only learns the form of language rather than its meaning. The article also shows, with some examples, that shortcut learning, a phenomenon often invoked in machine learning, is also present in LLM, i.e., learning systems that rely on spurious correlations in the data.
Published:
The study fine-tuned the GPT-3 large model to achieve long-form QA by manipulating browser search, i.e., giving long and meaningful complete answers to open-ended questions. The result is that more than half of the generated results are more satisfying than the answers given by humans, with higher accuracy and information validity.
Published:
Different researchers have different perspectives on the ideas proposed by LeCun, but in general this paper is extremely enlightening and leading. The paper proposes an architecture and training paradigm for building autonomous intelligences, combining concepts such as configurable predictive world models, behavior driven by intrinsic motivation, and hierarchical joint embedding architectures trained by self-supervised learning.
Published:
The option framework is reformulated as two parallel augmented MDPs. under this new formulation, all policy optimization algorithms are readily available for learning intra-option policy, termination policy, and master option. we apply AC algorithms on each augmented MDP and The DAC architecture is designed. Combined with the PPO algorithm, an empirical study is conducted on challenging robot simulation tasks.
Lab, Lab, 2023
This project mainly relies on the technical route of prompt learning and partial parameter fine-tuning of open-source large language models to realize a large-model intelligent assistant in the legal vertical field for professionals and the public, targeting legal documents, Q&A and legal data. I am responsible for framework design, deployment fine-tuning, evaluation session and interaction design. Check our project’s code, dataset and checkpoints in github.
Industry Research, Microsoft, Data Knowledge and Intelligence Group, 2024
Our work focused on improving Microsoft products’ accessibility through intelligent algorithms for automated detection and resolution of accessibility issues, along with establishing relevant evaluation frameworks.
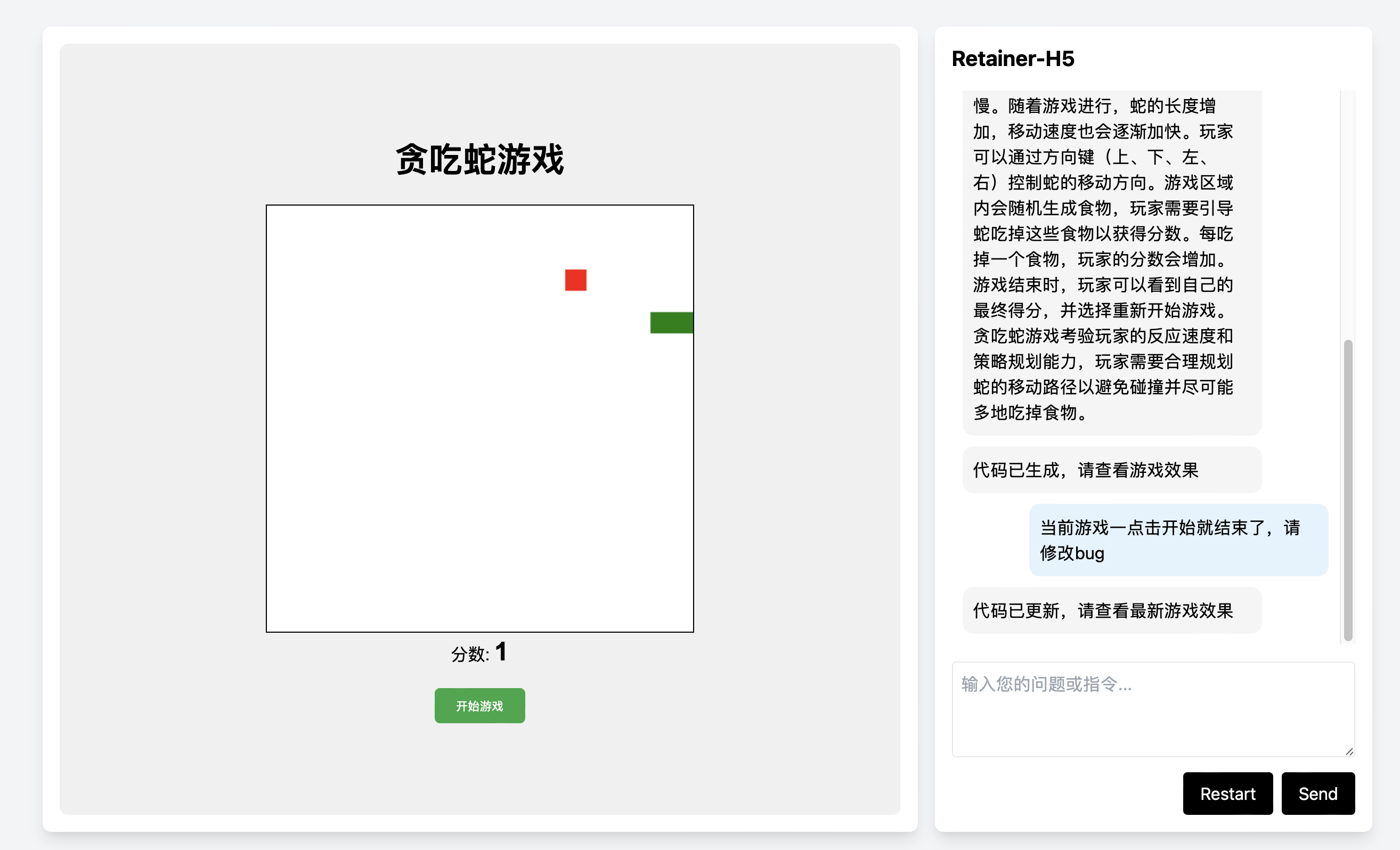
Research Project, Game Development, 2024
Retainer is an LLM-based agent for game development that enables natural language interaction to assist developers of all skill levels in game development and encapsulation.